Our Machine Learning Journey: From Zero to Customer Value in 12 months

PART 1
At Wootric we collect hundreds of thousands of NPS, CSAT and CES survey responses every week. We do this across different industries and product categories. Our customers then use our various integrations such as Salesforce, HubSpot, and Slack to route this feedback to relevant teams. Some of these customers like DocuSign and Grubhub have huge user base. This means even with a conservative sampling strategy they get hundreds of pieces of feedback daily.
The Challenge of Analyzing Qualitative Feedback
The quantitative aspects of feedback — NPS, CSAT scores, for example — are relatively easy to aggregate and analyze. It is the qualitative comments that provide rich insight into customer experience, but analysis of unstructured feedback is hard. Someone could read each piece of feedback one by one, but having a human read each comment obviously does not scale. If you can’t or don’t review what customers are telling you, then why have CX program to begin with? This is where machine learning saves the day.
Here is a concrete example of problem we needed to solve:
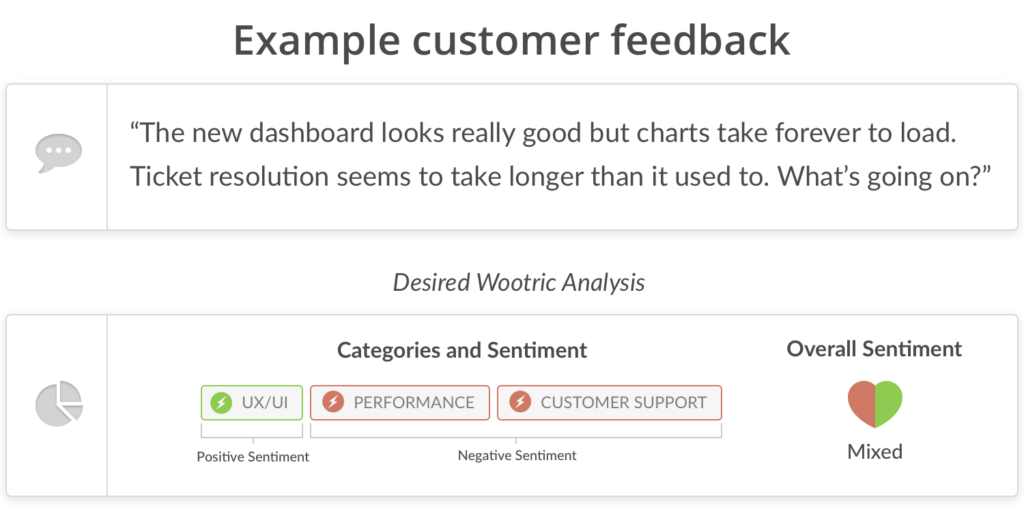
We set out to solve this multi-label classification and topic sentiment analysis problem for our customers. We knew that doing it at scale would require some sort of automation using machine learning (ML) and natural language processing (NLP). Machine learning requires lots of training data — in our case it meant we needed thousands of survey responses manually labeled into different categories. Luckily our customers have had the ability to manually categorize survey responses in our dashboard. In the last 3+ years, they have categorized thousands and thousands of comments. Fortuitous, but sometimes we would like to think we saw it coming. 😉 At this point, we have significant volume of training data, now we just needed to find the right machine learning algorithms to take a stab at the problem.
Sentiment Analysis
To get our feet wet in machine learning ecosystem, we thought we would start with sentiment analysis because there has been tons of research on this problem over last few years and there are several open source solutions claiming to solve this. We started with Stanford NLP library because it was and is still actively worked on and lots of great research papers have come out of this group. It took us about a week to get our heads around concepts of Tokenization, Lemmatization, Named Entity Recognition (NER), PoS tagging, Dependency parsing, Coreference Resolution, word embeddings and finally to embed the library into a REST API framework. The results were okay but not great for our use case. We **think** it’s because feedback comments belong to different domain — these are responses to questions as opposed to news article, blogs and tweets. Most of feedback is short, ranging from a couple of words to couple of sentences. This does not give enough “context” for algorithms to find the sentiment. An alternative solution would have been to train our own model using Stanford NLP library but we did not have engineering resources and bandwidth at that point in time. But we had something working. It was a baby step, but a step in the right direction.
Categorizing Feedback Comments
For feedback categorization, we also first looked into a hosted service and open source libraries. The most compelling, trainable and easy to get started solution at that point in time (mid 2016) was Google Cloud Prediction API where you upload a CSV of training data and in few minutes you get a model and REST API to make a prediction. This sounded like a tailor-made solution for us. After all, we had lots of training data that our customers had manually labeled. We were able to quickly format our responses and training labels in order to meet the Prediction API requirements, and saw some initial results.
Results were better for some sets of feedback but horrible for other sets. Dissecting further we realized that the customer feedback set where prediction was more accurate belonged to DevOps, Data Analytics and similar developer centric and data analytics. There was less success with feedback from e-commerce or other consumer-centric SaaS products. This made sense because most of our customers who spent their time manually labeling feedback had offerings catered to developers — such as New Relic, Docker etc. The bigger downside of Prediction API was that it was a black box so we did not have any ability to tune algorithms. Ironically, Google decided to deprecate Prediction API in favor of their Cloud ML Engine, driving us to improve our internal, customizable prediction methods instead.
Our experiments with Stanford NLP libraries and Google Prediction API gave us a good understanding of the complexity of problem we were tackling, provided more awareness of the ML ecosystem — people and research labs to follow, research papers to read — and finally helped us better understand the nuances of building machine learning models. It’s not as simple as having some training data, copy pasting some code from open source libraries and voila you have a ML solution. There are lots of hype and noise around what ML can do and how to go about doing it right.
At this point, we concluded that there was no shortcut and that we had to invest time focusing on high quality training data, going through various research papers, trying the algorithms in research papers using our training data and have nobs ( i.e. hyperparameters) tuned for our use case.
Delivering insights to customers
In April 2018, after six months in beta, we launched v1 of our product CXInsight™. The platform enables our customers to import and analyze customer feedback from any source. To date, we have analyzed 200,000+ comments pertaining to a wide spectrum of product categories and types of feedback — PaaS, SaaS, E-commerce, Mobile App reviews, employee reviews, social media, etc.
Of note, most of the data we’ve analyzed so far was originally collected using our competitors’ survey platforms. This is sweet validation of our goal: Regardless of how and where you collect customer feedback, Wootric gives you the best analysis.
In our next series of blog articles, we will talk about how we have used and are using:
- Bag of Words with Naive Bayes and SGD Classifier (Part II)
- word2vec with PCA, Logistic Regression, SVM and SGD Classifier
- Bidirectional LSTM
- CNN
- Custom word embeddings
- Productizing — DevOps around ML
- UX and UI
- Online learning and Human in the loop
Our goal has never been to build a generic text categorization tool. Rather, our focus is to build the best customer feedback analysis platform. We are also aware that our system is never going to be 100% correct so we have made it easy for our customers and our own team to be human in the loop.
I would be remiss not to thank Stanford NLP, Richard Socher, Lukas Biewald, Sebastian Ruder , Google ML research whose research papers, blogs, tutorials, videos and guidance have directly or indirectly helped us build CXInsight product.
Please stay tuned to our Engineering Blog for next series of articles on this topic. The Hacker News discussion is here.



