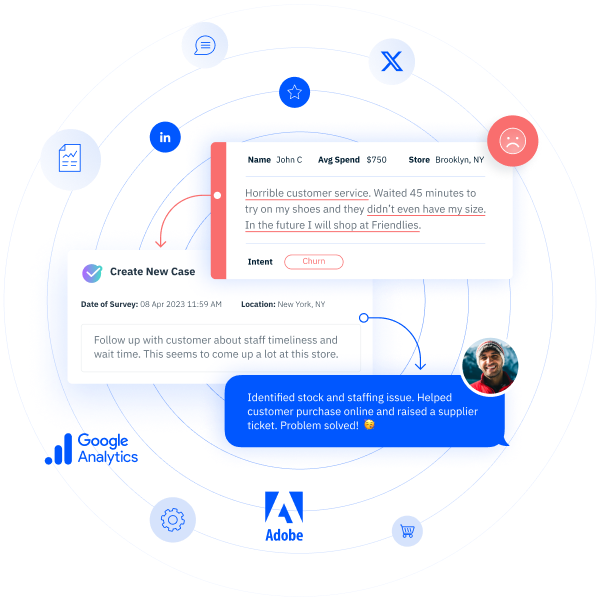
How to Train AI to Analyze Your Customer Feedback

Customer comments are the lifeblood of any CX program, giving you the “why” behind customers’ NPS, CES, and CSAT scores. But until recently, it’s been nearly impossible to make sense of feedback from hundreds of customers at a time. Using artificial intelligence (AI) to automate text analysis gives you the consistent and fast insights you need, at scale.
That said, automated text analysis isn’t just about technology. Humans need to put in the time upfront to teach the machine, by providing an accurately tagged set of feedback for AI to work from. The quality of that training data sets up the quality of your text analytics results, or as the old saying goes “garbage in, garbage out”.
Let’s look at what you need to be successful with automated text analytics. We’ll dig into the basics of text analytics, the inconsistencies of manual tagging, and how to create good training data and models.
A quick primer on AI training sets
Analyzing customer feedback from unstructured text can be complex. In one sentence a customer may talk about a variety of topics, offering negative, neutral, or positive feedback (sentiment) about each of them. It’s the job of machine learning to recognize what the customer is talking about and identify how they are feeling about those topics. With text analytics, it only takes an instant to:
- Tag comments / categorize themes
- Assign sentiment to each of the tags and the comment overall
- Aggregate results to find insights
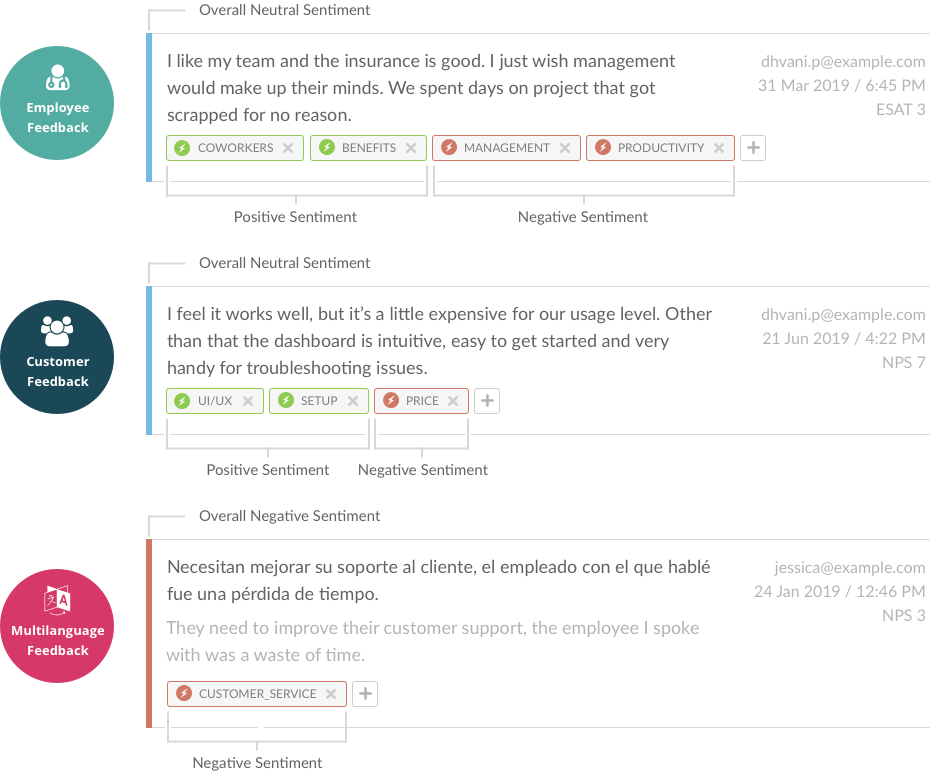
Text analyzed for sentiment and themes
Again, machine learning is only as good and accurate as the data set you (the humans) provide to train the algorithm. So you need to do it right.
At Wootric, we have a lot of experience helping teams create training datasets. While we have sets of tags that are specific to various industry verticals, we also build custom machine learning models for many customers. Custom models are helpful for companies that are in a new vertical or a unique business.
Training model process
For the most part, companies have a good feel for what their users/customers are talking about and the topic tags they need. If they’re not sure, we can analyze their data and work with them to help them think through a set of tags to get them started. Once they have a set of agreed tags, they start creating the training data.
The process for creating this training dataset goes something like this.
- Decide what tags are important to your business
- Create definitions for those tags so everyone knows exactly what the tags mean
- Pull 100-200 customer comments
Our customer assembles a team of at least 3-5 people who independently review each comment and determine:
- If the comment sentiment is overall positive, neutral, or negative
- Which tags apply to that comment
That last point is where things get interesting for a data analyst like me.
Manual tagging: an inconsistent truth
Many companies still believe having human tagging and analysis is superior to AI. We’ve seen one employee hired full-time to pour over spreadsheets, organizing data and pulling insights, which takes A LOT of time. Other companies bring in a team of people (the interns!), which introduces inconsistencies. Not only is it expensive and time-intensive, manual tagging isn’t necessarily accurate.
These same inconsistencies appear when creating training datasets because the process starts with manual tagging. Customer teams creating training data are always surprised by the level of disagreements on “defined” tags. It can take a few rounds of work to iron these out.
Tag definitions vary
Not all tags carry the same level of complexity. Some tags make it easy for people to agree upon a definition, while others may be more ill-defined. Vague tags tend to invite more disagreement between human labelers who label the same dataset independently.
Let’s look at a couple of examples from the software industry:
- “MOBILE” — applied to any feedback containing references to a mobile app or website functionality. This should be straightforward for a group of human labelers to apply similarly, and would most likely only result in a few disagreements between them.
- “USER EXPERIENCE” — a more complex phrase with many different definitions of what could be included in a user’s experience. When a comment mentions search functionality, is that UX? How about when they say something like “While using the search bar, I found information on…“? Or even “Great product”? Because there is so little clarity on what fits in this category, the training team will surely disagree, leading to more rounds of tagging and defining.
The good news is that at the end of the process, after a few rounds of defining the tags and applying them, the team REALLY knows what is meant by a given tag. The definition is sharper and less open to interpretation. This makes the machine learning categorization more meaningful, and more actionable for your company, which leads to an improved customer experience.
Getting to a good training model
Let’s look at a real-world example of creating a training set, and the level of label agreement between the people creating those labels.
A recent enterprise customer used 8 human labelers on the same initial set of 100 comments, and we then evaluated the labeler-agreement of each tag. During this exercise, each labeler worked independently , and we charted the agreement scores.
In the following two charts, the number in each cell represents the strength of the agreement from 0 – 1 between two labelers (F1-Score calculated from Precision and Recall values).
- 1.0 would be the ideal labeler agreement value.
- 0 means no agreement.
The lower row of the chart contains the average agreement across all cells for that labeler.
In Figure 1, it’s clear that the tag is fairly well-defined, which results in an overall average labeler agreement of ~0.83. This is on the higher end of what we typically see.
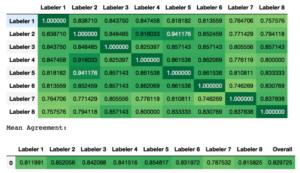 Figure 1 – agreement on a well-defined tag
Figure 1 – agreement on a well-defined tag
In other words, even a well-defined tag doesn’t garner complete agreement between labelers. Labeler 5, our most effective labeler, only scored a 0.85 average. Labeler 1 and 8, with an F-1 score of .75, didn’t apply the tag, in the same way, a significant portion of the time. But it’s still considered successful.
Now, look at Figure 2, which shows the first-round results of the team’s effort to consistently apply a more complex tag. It resulted in an overall average labeler agreement of only ~0.43.
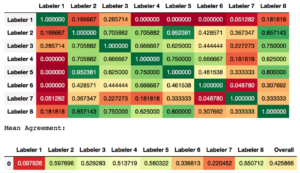 Figure 2 – disagreement on a vague tag
Figure 2 – disagreement on a vague tag
For the same group of labelers tagging at the same time, two different tags demonstrate nearly 2x difference in overall agreement — showing again that even we humans aren’t as good at manually categorizing comments as we would like to think.
Even when teams agree on 1) what tags to use and 2) the definition of each tag, they don’t necessarily wind up applying tags in the same way. It takes a few rounds for teams to come close enough to consensus to be useful for machine learning.
Ready for autocategorization
Text analytics is not a perfect science. When are the label agreement results ready for prime time? Typically, we consider a model good enough to deploy once the F-1 score is around 0.6 (give or take a bit based on other factors). Like most things in life, when you invest more time upfront — in this case boosting F-1s with additional rounds of tagging/defining — you typically end up with better results.
Makes sense of customer feedback with InMoment CXInsight text analytics.