Choosing the Best Text Analysis Software for Your Business

In a business landscape that has become digital-first, where consumers’ expectations can change overnight, it has never been more important to the success of your business to be able to understand and leverage data. One of this environment’s most challenging yet rewarding aspects is making sense of unstructured text data such as online reviews or customer emails. Most businesses achieve this by utilizing text analysis software. Text analysis software, also known as text analytics software, has become indispensable for businesses aiming to extract actionable insights from textual data to improve the customer experience.
What is Text Analysis Software?
Text analysis software utilizes natural language understanding (NLU), a subset of natural language processing (NLP), to analyze text data. Given the unstructured nature of text, these tools process textual input to generate labels, tags, and insights. Text analysis has become a critical component of analytics and business intelligence, enabling companies to derive meaningful information from unstructured data sources such as emails, social media, online reviews, and more.
Whether it’s analyzing online reviews, customer feedback, or any other form of unstructured data, these tools can sift through large amounts of information and highlight important elements. By converting raw data into actionable insights, businesses can improve their strategies and make more informed decisions.
Why Your Business Needs Text Analysis Software
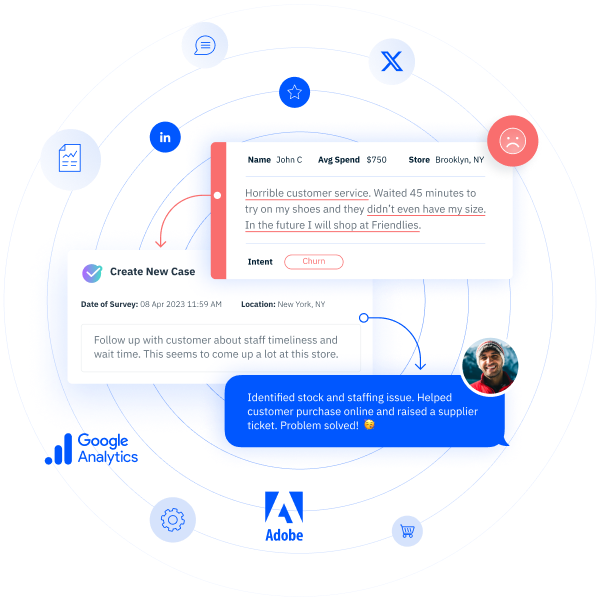
Most businesses are already collecting vast amounts of data, whether in the form of surveys, reviews, order history, contact center complaints, or other forms of data. However, collecting this data can be time-consuming and inefficient without the proper tools. By utilizing text analysis software, your business can be more efficient and realize benefits such as increased customer insights, improved operational efficiency, and others.
Types of Text Analysis Software
There are various types of text analytics software, each with its unique strengths. Some focus on sentiment analysis, which gauges emotions behind the text data. Others specialize in predictive analytics, using past data to forecast future trends. Text analytic software also prioritizes text mining, digging deep into the data to find hidden insights.
Regardless, when it comes to the kinds of text analysis software you’ll see in the market, they will all fall under two categories: self-service text analysis software and traditional text analysis software. The one that you end up choosing will depend on a variety of factors, as each type of software serves different purposes for different types of users.
Self-Service Analysis Tools
Self-service text analysis software is designed for users with little to no technical knowledge of text analysis tools. These platforms often feature drag-and-drop interfaces, prebuilt templates, and interactive dashboards, making them accessible to just about anyone.
Examples:
- Analyzing customer emails for sentiment trends
- Creating dashboards to track marketing campaign performance
Traditional Text Analysis Tools
Traditional text analysis tools are geared toward technical professionals such as data analysts or data scientists. They offer extensive customization options, allowing users to create and fine-tune their algorithms and models. This flexibility is ideal for complex, large-scale projects that require specific, tailored solutions.
Due to their complexity, these tools may require a higher level of involvement or technical expertise, such as managed services or a dedicated representative. They may require ongoing support from IT departments or data science teams to maintain and update.
Examples:
- Ingesting social media data to detect emerging trends.
- Developing custom models to predict customer churn.
By carefully evaluating these factors, businesses can select the text analysis tool that best fits their specific requirements and enhances their ability to leverage text data for strategic advantage.
Things to Look for in Text Analysis Software
Selecting the right text analysis software is crucial for leveraging unstructured data to derive actionable insights. While features may vary from one software product to another, there are some key features you should consider when evaluating a software product for your business.
Natural Language Processing Capabilities
- Language Identification: The ability to detect and process multiple languages, ensuring the software can handle diverse data sources.
- Tokenization: Breaking down text into smaller components, such as words or phrases, for detailed analysis.
- Part of Speech Tagging: Identifying the grammatical components of text (e.g., nouns, verbs, adjectives) to understand the structure and context.
Sentiment Analysis
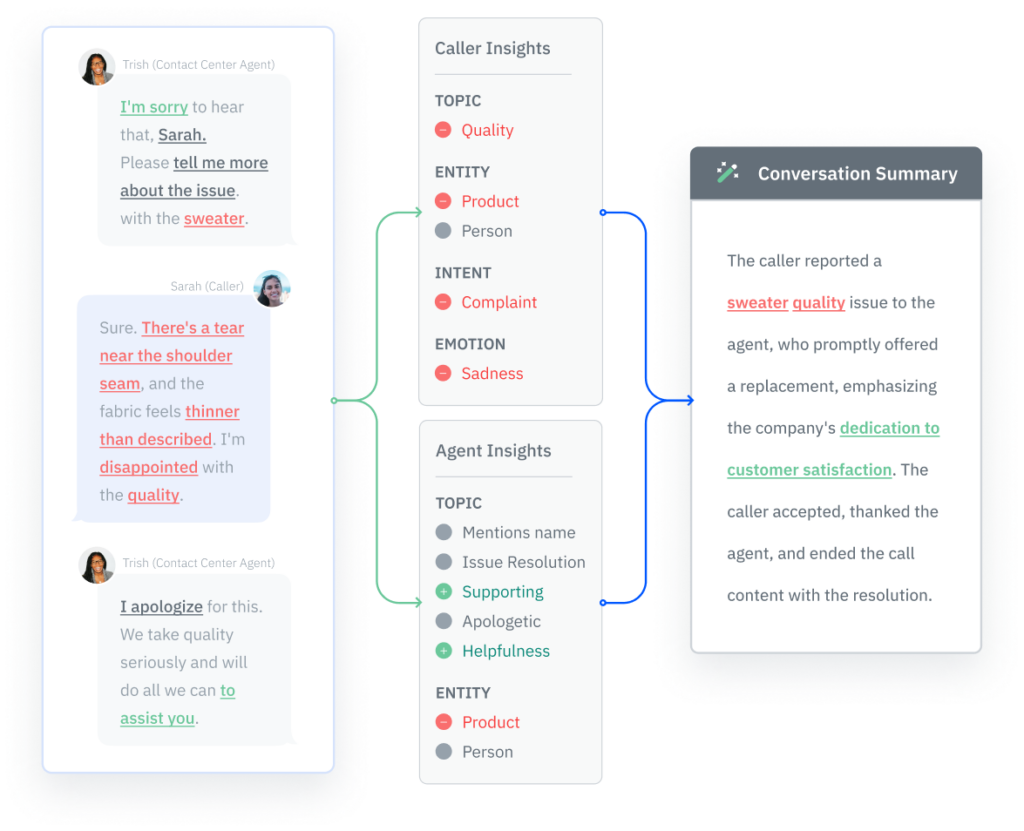
- Sentiment Scoring: Determining the sentiment (positive, negative, neutral) of the text to gauge customer opinions or feedback.
- Emotion Detection: Identifying specific emotions, such as happiness, anger, or sadness, for more nuanced insights.
Text Classification and Categorization
- Automated Tagging: Automatically assigning tags or labels to text based on predefined categories or machine learning models.
- Custom Taxonomies: Allowing users to create custom classification schemes to fit specific business needs.
Data Visualization
- Interactive Dashboards: Providing visual representations of text analysis results through charts, graphs, and other visualization tools.
- Real-time Analytics: Offering real-time updates and visualizations to monitor ongoing trends and changes.
Integration and Compatibility
- API Access: Offering APIs for seamless integration with other business systems and data sources.
- Data Source Connectivity: Connecting with various data sources such as social media, CRM systems, emails, documents, and more.
Benefits of Text Analysis Software
Incorporating text analysis software into your business operations can offer a multitude of advantages. Here are some key benefits that can significantly enhance your organization’s efficiency, decision-making, and overall performance:
Enhanced Customer Insights
Text analysis software can process vast amounts of customer feedback from sources such as social media, emails, and online reviews. By determining the sentiment behind customer communications, businesses can gain valuable insights into customer satisfaction and loyalty, allowing them to address issues proactively and improve customer relationships and uphold their brand reputation.
Businesses can also identify recurring themes and patterns in customer interactions, which allows them to uncover emerging trends and shifts in customer preferences. This enables them to adapt their products, services, and marketing strategies to better align with customer needs.
Improved Decision-Making
With text analysis software, businesses can transform unstructured text data into structured insights that inform strategic decisions. Furthermore, text analysis can also be used to predict future trends based on historical data.
For instance, analyzing past customer reviews and feedback can help businesses anticipate future customer behavior and preferences, allowing for more accurate forecasting and planning. This data-driven approach helps managers and executives make more informed and effective decisions, leading to better business outcomes.
Increased Operational Efficiency
Text analysis software automates the extraction and classification of key information from large volumes of text data, significantly reducing the time and effort required for manual data processing.
By efficiently categorizing and prioritizing text data, text analysis software helps organizations allocate resources more effectively. For example, customer service teams can prioritize inquiries based on sentiment and urgency which ensures that critical issues are addressed promptly.
Improved Employee Engagement
Internally, text analysis software can be used to gauge employee sentiment through surveys, feedback forms, and other communications. Understanding how employees feel about various aspects of their work environment can help management make informed decisions to improve employee satisfaction and engagement.
Text analysis software can also be used to analyze text data from performance reviews and other employee interactions to provide insights into workforce performance and highlight areas for development and training.
The benefits of text analysis software extend across various facets of business operations, from customer service and marketing to compliance and employee engagement. By leveraging the power of text analysis, organizations can unlock valuable insights from their unstructured data, leading to improved decision-making, increased efficiency, and a competitive edge in the market.
Who Uses Text Analysis Software?
Text analysis software is a versatile tool that can be employed across various departments within a business, each leveraging its capabilities to enhance its specific functions. Here are some key areas of business where text analysis software is commonly used, along with how professionals in those areas utilize it:
Data Scientists
Data scientists are primarily responsible for analyzing and interpreting complex data to help businesses make informed decisions. They can use text analysis software for:
- Algorithm Development: Data scientists use text analysis software to develop and refine natural language processing (NLP) algorithms that can classify, tag, and extract meaningful insights from text data.
- Sentiment Analysis: They apply sentiment analysis to gauge customer sentiment from reviews, social media posts, and other text sources, helping the company understand public perception and improve customer experience.
- Predictive Modeling: By analyzing historical text data, data scientists can create predictive models that forecast trends and customer behavior, aiding in strategic planning.
Marketing Teams
Marketing professionals are tasked with promoting products and services, understanding market trends, and engaging with customers effectively. They use text analysis software for:
- Campaign Analysis: Marketers use text analysis software to assess the performance of marketing campaigns by analyzing customer feedback, social media interactions, and online reviews.
- Audience Segmentation: Text analysis helps in segmenting audiences based on their interactions and sentiments, allowing marketers to tailor their messages for different customer groups.
- Content Optimization: By analyzing which keywords and phrases resonate most with their audience, marketers can optimize their content for better engagement and conversion rates.
Customer Service Teams
Customer service representatives are responsible for managing customer inquiries, resolving issues, and ensuring customer satisfaction. They can use text analysis for:
- Sentiment Detection: Text analysis software can detect the sentiment of customer emails, chat messages, and social media posts, helping representatives prioritize and address negative feedback promptly.
- Trend Identification: By identifying common issues and complaints through text analysis, customer service teams can proactively address recurring problems and improve service quality.
- Automation: Automated text analysis can classify and route customer queries to the appropriate departments or representatives, enhancing response times and efficiency.
Sales Teams
Sales professionals focus on generating leads, closing deals, and building customer relationships to drive revenue.
- Lead Qualification: Text analysis can help sales teams analyze and prioritize leads based on the language and sentiment used in customer interactions, improving the likelihood of conversion.
- Customer Insights: By analyzing past communications and feedback, sales teams can gain insights into customer preferences and pain points, enabling more personalized and effective sales pitches.
- Pipeline Management: Text analysis software can track and analyze sales emails and call transcripts to identify trends and patterns, helping sales managers forecast pipeline health and performance.
Human Resources
Human resources (HR) professionals manage recruitment, employee relations, and organizational development. They use text analysis for:
- Employee Sentiment Analysis: Text analysis tools can evaluate employee feedback from surveys, performance reviews, and internal communications to gauge overall sentiment and engagement levels.
- Recruitment: Analyzing text from resumes and cover letters can help HR teams identify the best candidates for open positions based on specific keywords and experience levels.
- Policy Effectiveness: HR can use text analysis to assess the effectiveness of company policies by analyzing employee feedback and identifying areas for improvement.
Finance Teams
Finance professionals manage the company’s financial planning, analysis, and reporting. They can use text analysis for:
- Expense Analysis: Text analysis can help categorize and analyze free-text data in expense reports, uncovering spending patterns and identifying cost-saving opportunities.
- Risk Management: Finance teams can use text analysis to monitor financial news and reports for early warning signs of market changes or potential risks.
- Compliance: By analyzing communications and transaction records, finance teams can ensure adherence to regulatory requirements and detect potential compliance issues.
Text analysis software is a valuable asset for various departments within a business, from data science and marketing to customer service and HR. Each professional group utilizes the software to extract actionable insights from unstructured text data, enabling better decision-making, enhanced efficiency, and improved overall performance. By integrating text analysis into their workflows, businesses can harness the full potential of their data and drive success across all areas.
Challenges with Text Analysis Software
While text analysis software offers numerous advantages, its deployment, and effective use come with several challenges that organizations need to address to maximize its potential. These challenges include:
- Data quality and preprocessing
- Language and content understanding
- Integration with existing systems
- Scalability
- Privacy and security concerns
These challenges can be avoided through strategic planning, advanced technology, and cross-functional collaboration. It is also important to ensure that the software is implemented with users being trained on it in the most efficient manner.
How to Purchase Text Analysis Software
Selecting the right text analysis software for your business is a critical decision that can significantly impact your organization’s ability to harness insights from unstructured text data. Here’s a step-by-step guide to help you navigate the purchasing process effectively:
1. Define Your Requirements
Start by understanding the specific needs of your business. Are you looking to improve customer service, enhance marketing strategies, monitor brand reputation, or gain insights from internal communications?
Next, list must-have features such as sentiment analysis, entity recognition, keyword extraction, language support, integration capabilities, and user-friendliness. Ensure the software can scale with your business and adapt to evolving needs. Flexibility in terms of deployment (cloud-based or on-premises) is also important.
2. Conduct Market Research
Research the available text analysis software solutions in the market. Use review sites, industry reports, and technology forums to gather information on the top contenders.
Compare vendors based on features, pricing, customer reviews, and industry reputation. Look for case studies or success stories from businesses similar to yours.
Arrange for product demonstrations to see the software in action. Pay attention to accuracy, speed, and value of insights during these demos.
3. Evaluate Total Cost of Ownership
Consider the upfront costs, including licensing fees, setup costs, and any required hardware or infrastructure investments. Factor in maintenance fees, subscription costs, potential costs for updates or additional features, and support services. Be aware of any hidden costs, such as training, customization, and integration with existing systems.
4. Assess Integration and Compatibility
Integration with Existing Systems:
Ensure the software can integrate seamlessly with your current IT infrastructure, including CRM, ERP, and other data management systems.
Data Import and Export:
Check if the software supports easy data import/export to facilitate smooth data migration and interoperability with other tools.
5. Consider User Experience
Choose software that is user-friendly and requires minimal training. A good user interface can significantly enhance adoption rates among employees. Evaluate the vendor’s customer support services. Look for comprehensive training programs, documentation, and community forums.
Purchasing text analysis software is a strategic investment that requires careful consideration of your business needs, budget, and technical requirements. By following these steps—defining your requirements, conducting thorough research, evaluating costs, ensuring compatibility, considering user experience, ensuring security, pilot testing, and negotiating terms—you can select the right solution that will provide valuable insights and drive business success.
Implementation of Text Analysis Software
Implementation of text analysis software should be done in a systematic and planned manner. It’s important to train your team on how to use the software and understand the insights it provides. You should also regularly evaluate the software’s performance and make adjustments as needed to ensure it continues to meet your business needs.
Text Analysis Software Trends
In today’s digital age, text analytics solutions continue to evolve. One emerging trend is the increasing use of AI in text analytics, enhancing the software’s ability to understand and interpret human language. Another trend is the growth of real-time analysis, enabling businesses to respond quickly to emerging trends or issues. The future of text analysis software looks promising, with new advancements on the horizon that will further enhance its functionalities.
Text Analysis Software with InMoment
If you are looking to improve your text analysis, consider InMoment as your partner. InMoment was recently named a leader in the Forrester Text Mining & Analytics Wave. Recognized for our knowledge-based AI and best-in-class text extraction, the InMoment platform is the best choice for enterprises looking to take their text analytics to the next level. You can read the full report here!

REPORT
InMoment Named a Leader in The Forrester Wave™: Text Mining And Analytics Platforms, Q2 2024
Learn how InMoment is pioneering innovative solutions for businesses to extract insights and drive meaningful change from their unstructured text data.